AWSで作るはじめてのETL【Glue Jobフロー】
概要
Glue JobがS3に格納されたcsvファイルを読み込み、Redshiftにインサートするように実装を行う。
Glue遷移
Glueへ遷移
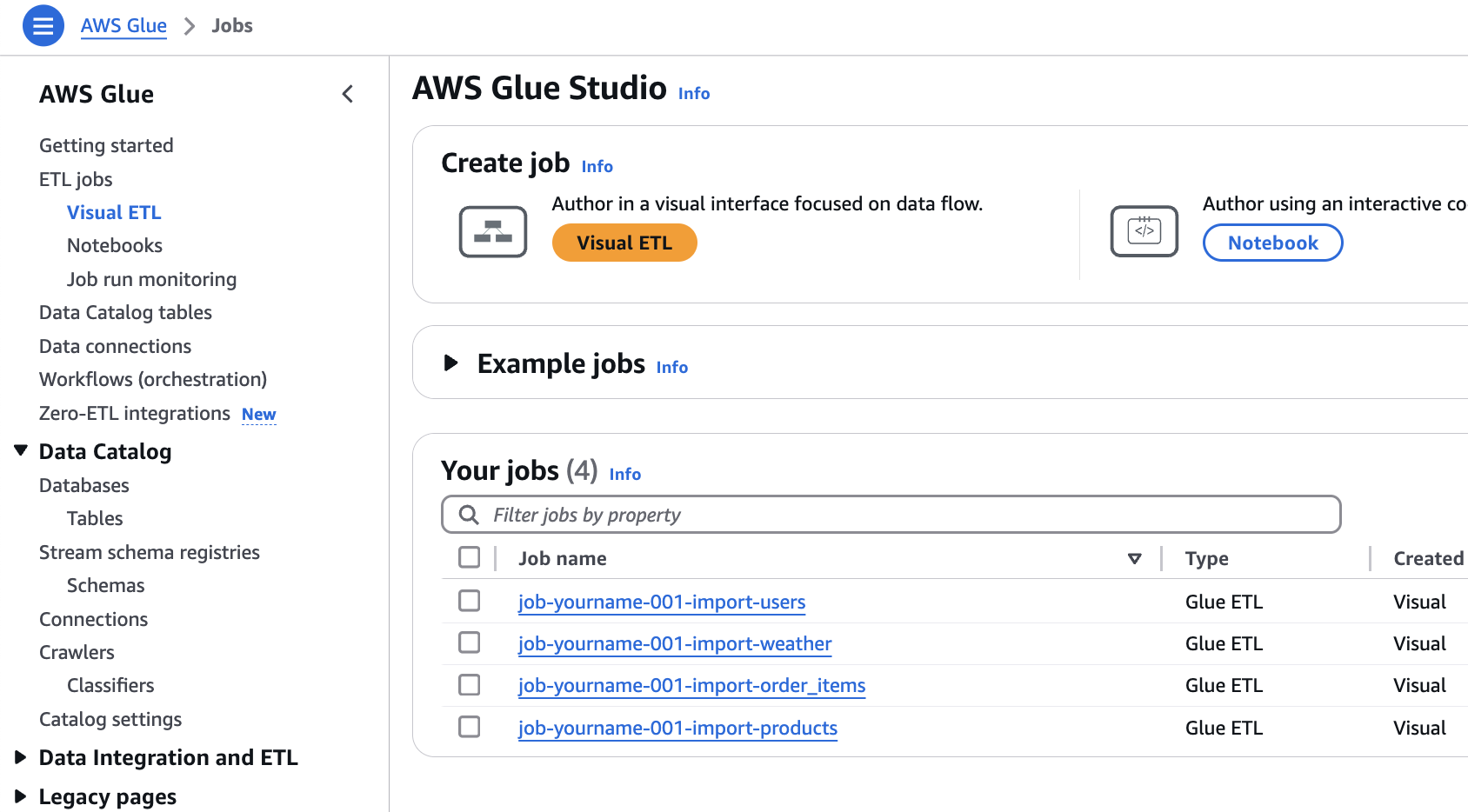
ジョブ編集
job-[自分の名前]-[番号]-import-users をクリック
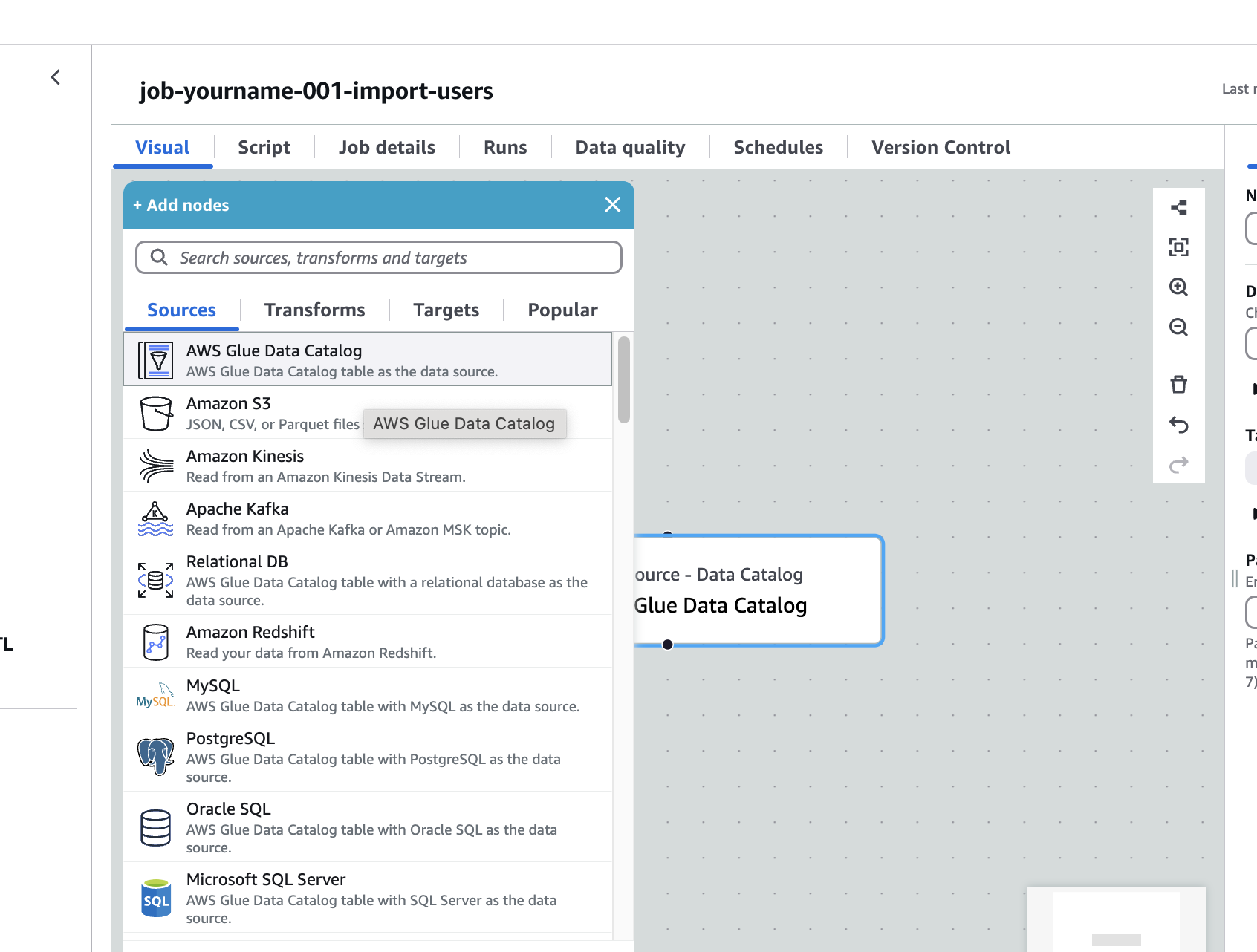
DataCatalog追加
DataCatalogを選択
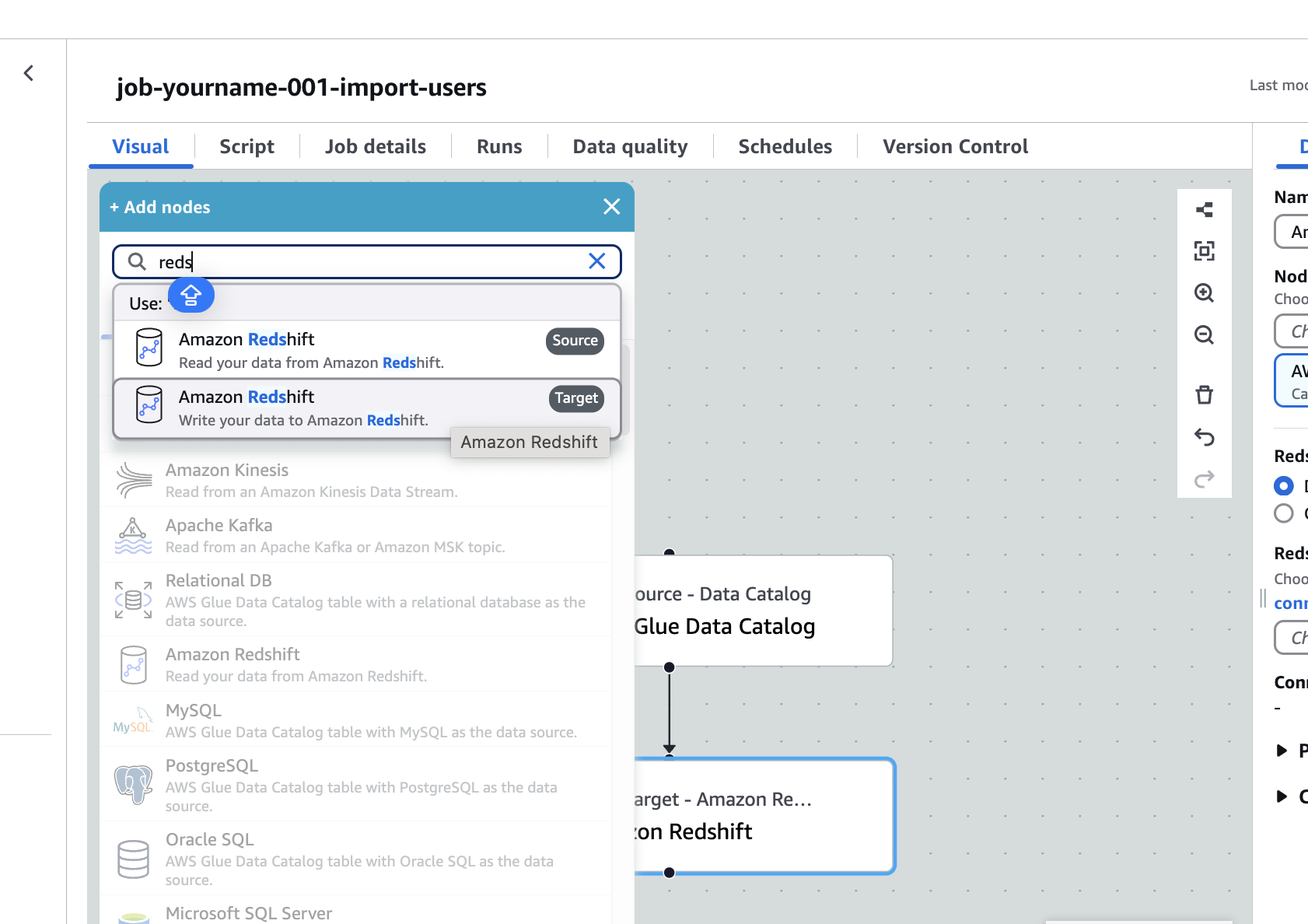
Redshift
Amazon Redshift (Target)を選択
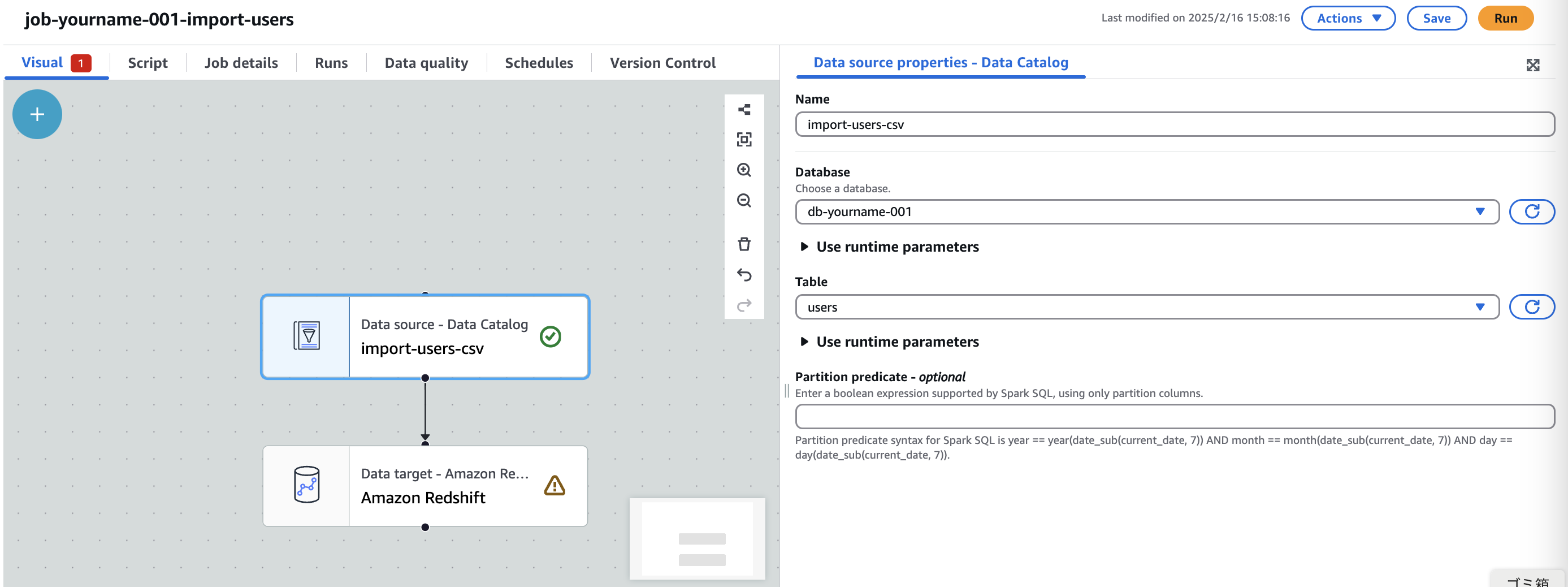
DataCatalog Node設定
- Name:
import-users-csv - Database:
db-[自分の名前]-[番号] - Table:
users
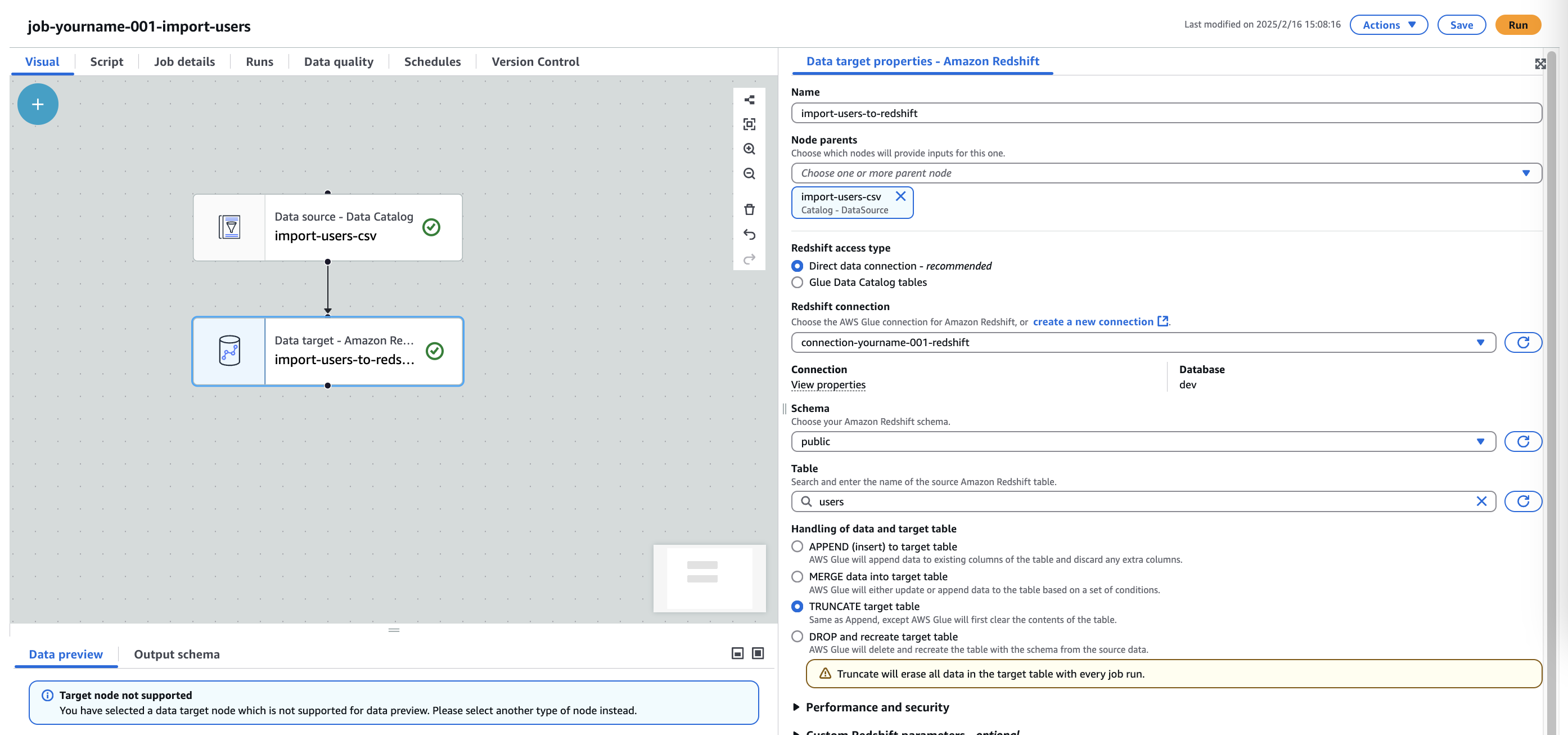
Redshift Node設定
- Name:
import-users-to-redshift - Node parents:
import-users-csv (変更なし) - Redshift connection:
connection-[自分の名前]-[番号]-redshift - Redshift access type:
Direct data connection - recommended - Schema:
public - Table:
users - Handling of data and target table:
TRUNCATE target table
Save
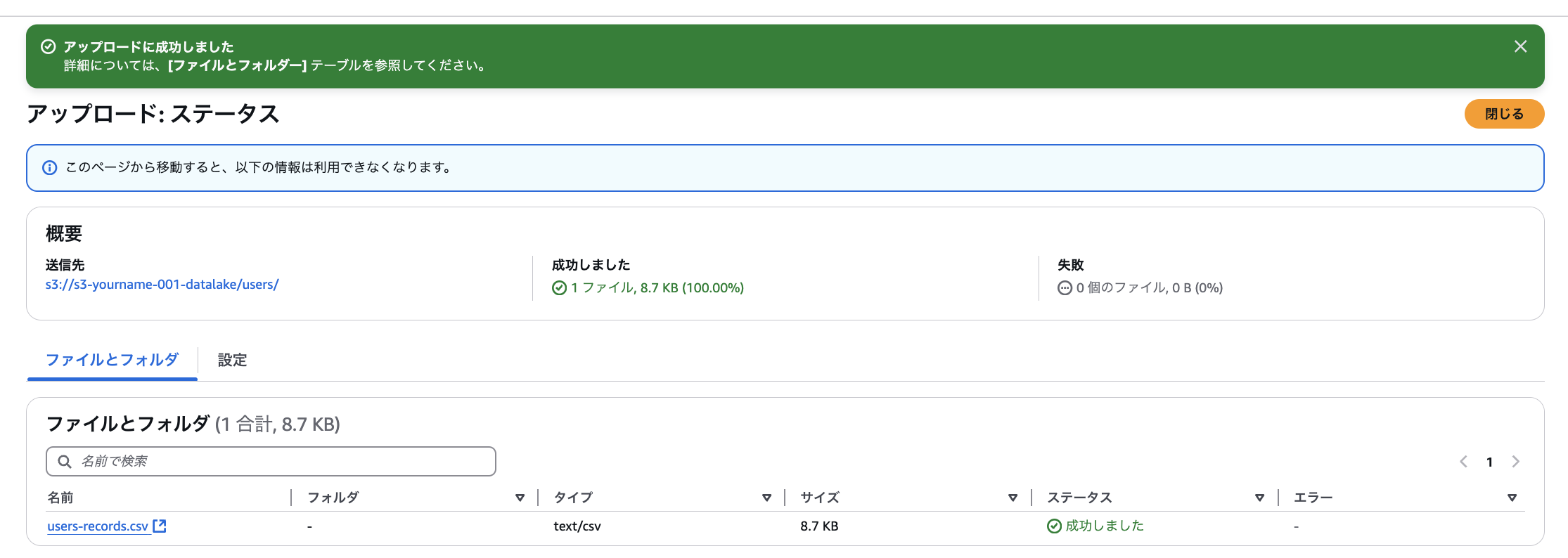
データレイクテーブルファイルアップロード
s3-[自分の名前]-[番号]-datalakeのusersフォルダに下記ファイルをアップロードする
名前は users.csv にすることに注意
前回アップロードしたファイルを上書きして良い
Glue Job確認
Glue jobの「Runs」より、ジョブが動いていることを確認
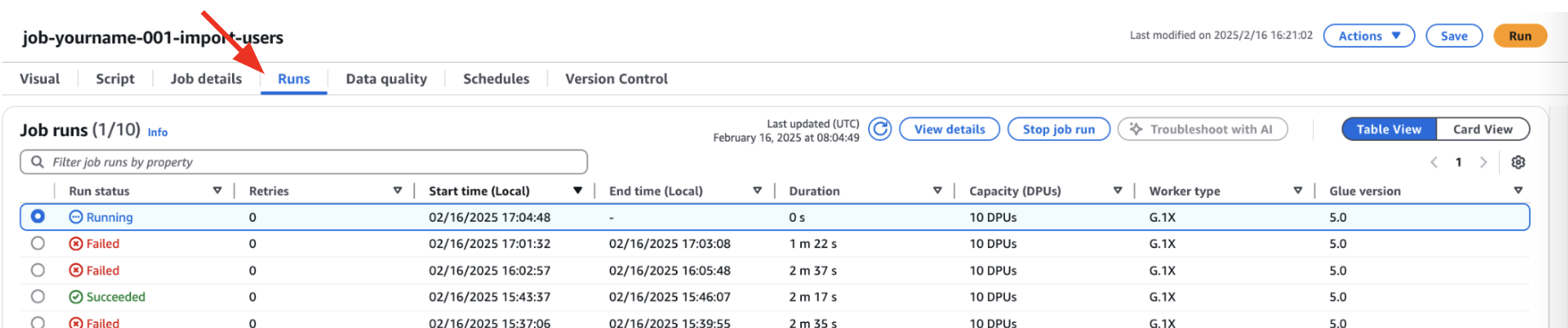
Glue Job 取り込み成功
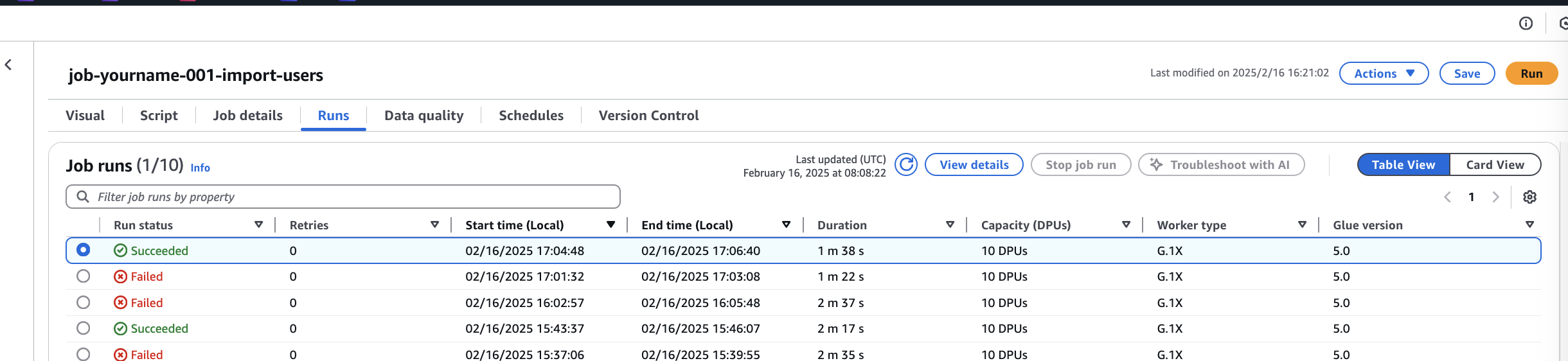
レコード登録確認
Redshiftのクエリエディタより、レコードを確認する
クエリエディタの接続については Redshiftテーブル を参照
レコードが登録されていれば成功
参考:実行SQL
sql
SELECT * FROM "dev"."public"."users";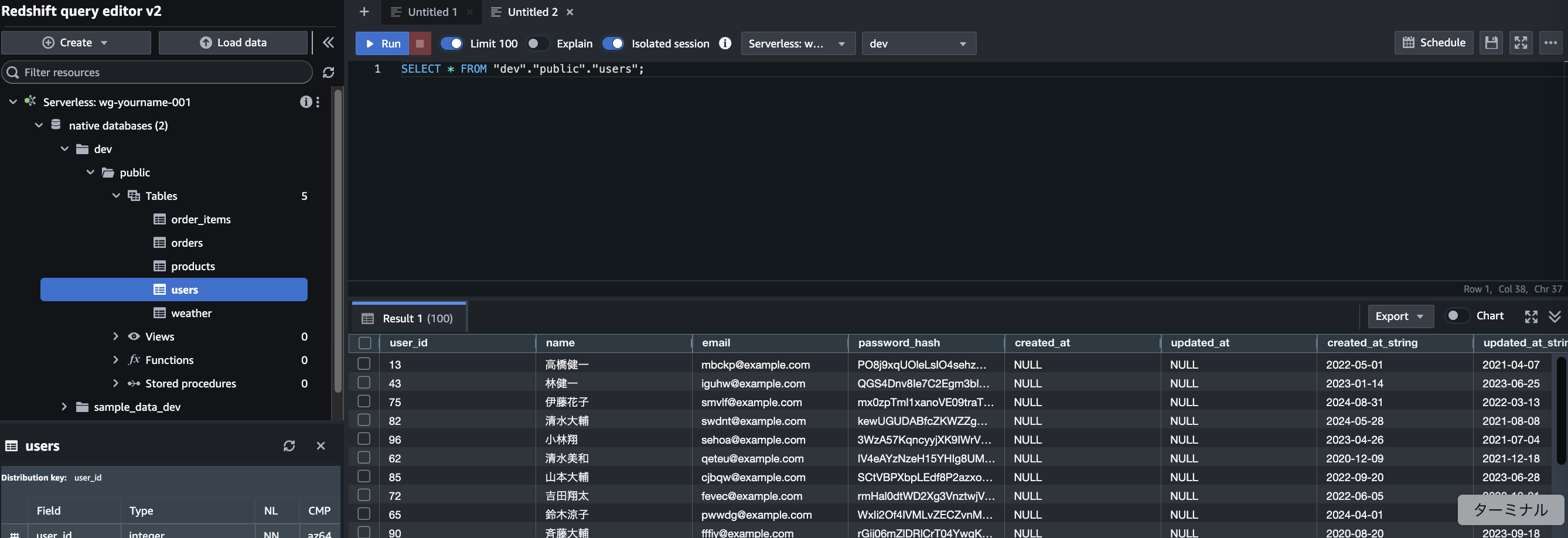
他Job編集
そのほかのジョブについても「ジョブ編集」->「レコード登録確認」同様に編集する
なお、それぞれの情報は下記の通り設定する
import-products
DataCatalog Node設定
- Name:
import-products-csv - Database:
db-[自分の名前]-[番号] - Table:
products
- Name:
Redshift Node設定
- Name:
import-products-to-redshift - Node parents:
import-products-csv (変更なし) - Redshift connection:
connection-[自分の名前]-[番号]-redshift - Redshift access type:
Direct data connection - recommended - Schema:
public - Table:
products - Handling of data and target table:
TRUNCATE target table
- Name:
データレイクテーブルファイルアップロード
- S3フォルダ:
products/ - ファイル: products.csv
- S3フォルダ:
import-orders
DataCatalog Node設定
- Name:
import-orders-csv - Database:
db-[自分の名前]-[番号] - Table:
orders
- Name:
Redshift Node設定
- Name:
import-orders-to-redshift - Node parents:
import-orders-csv (変更なし) - Redshift connection:
connection-[自分の名前]-[番号]-redshift - Redshift access type:
Direct data connection - recommended - Schema:
public - Table:
orders - Handling of data and target table:
TRUNCATE target table
- Name:
データレイクテーブルファイルアップロード
- S3フォルダ:
orders/ - ファイル: orders.csv
- S3フォルダ:
import-order_items
DataCatalog Node設定
- Name:
import-order_items-csv - Database:
db-[自分の名前]-[番号] - Table:
order_items
- Name:
Redshift Node設定
- Name:
import-order_items-to-redshift - Node parents:
import-order_items-csv (変更なし) - Redshift connection:
connection-[自分の名前]-[番号]-redshift - Redshift access type:
Direct data connection - recommended - Schema:
public - Table:
order_items - Handling of data and target table:
TRUNCATE target table
- Name:
データレイクテーブルファイルアップロード
- S3フォルダ:
order_items/ - ファイル: order_items.csv
- S3フォルダ:
import-weather
DataCatalog Node設定
- Name:
import-weather-csv - Database:
db-[自分の名前]-[番号] - Table:
weather
- Name:
Redshift Node設定
- Name:
import-weather-to-redshift - Node parents:
import-weather-csv (変更なし) - Redshift connection:
connection-[自分の名前]-[番号]-redshift - Redshift access type:
Direct data connection - recommended - Schema:
public - Table:
weather - Handling of data and target table:
TRUNCATE target table
- Name:
データレイクテーブルファイルアップロード
- S3フォルダ:
weather/ - ファイル: weather.csv
- S3フォルダ: